Like 1980s hair bands, male cockatoos woo females with flamboyant tresses and killer drum solos.
Male palm cockatoos (Probosciger aterrimus) in northern Australia refashion sticks and seedpods into tools that the animals use to bang against trees as part of an elaborate visual and auditory display designed to seduce females. These beats aren’t random, but truly rhythmic, researchers report online June 28 in Science Advances. Aside from humans, the birds are the only known animals to craft drumsticks and rock out. “Palm cockatoos seem to have their own internalized notion of a regular beat, and that has become an important part of the display from males to females,” says Robert Heinsohn, an evolutionary biologist at the Australian National University in Canberra. In addition to drumming, mating displays entail fluffed up head crests, blushing red cheek feathers and vocalizations. A female mates only every two years, so the male engages in such grand gestures to convince her to put her eggs in his hollow tree nest.
Heinsohn and colleagues recorded more than 131 tree-tapping performances from 18 male palm cockatoos in rainforests on the Cape York Peninsula in northern Australia. Each had his own drumming signature. Some tapped faster or slower and added their own flourishes. But the beats were evenly spaced — meaning they constituted a rhythm rather than random noise.
From bonobos to sea lions, other species have shown a propensity for learning and recognizing beats. And chimps drum with their hands and feet, sometimes incorporating trees and stones, but they lack a regular beat.
The closest analogs to cockatoo drummers are human ones, Heinsohn says, though humans typically generate beats as part of a group rather than as soloists. Still, the similarity hints at the universal appeal of a solid beat that may underlie music’s origins.
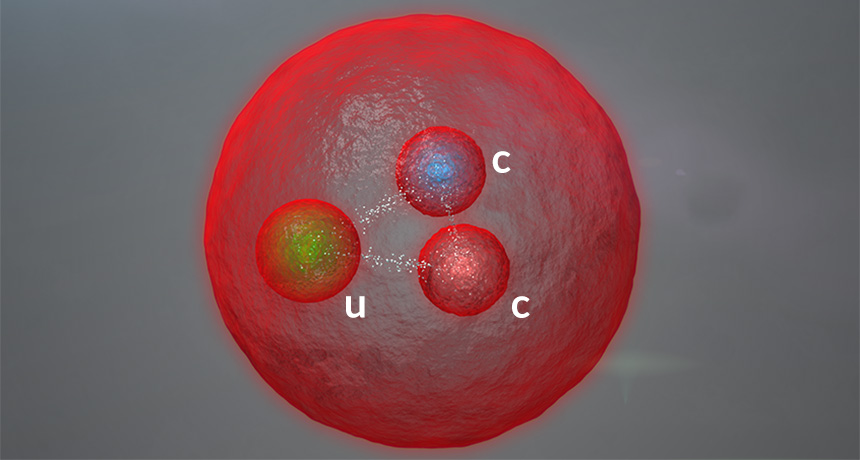
A newly discovered particle is dishing out a double dose of charm.
The newcomer is a baryon, meaning that it’s composed of three smaller particles called quarks — in this case, two “charm” quarks and one “up” quark. Detected by the LHCb experiment at CERN, the European physics laboratory near Geneva, the baryon is the first to be discovered with two charm quarks, LHCb scientists reported July 6 at the European Physical Society Conference on High Energy Physics in Venice, Italy. Scientists produced the particle by ramming protons together at CERN’s Large Hadron Collider and sifting through the aftermath. Baryons can be composed of a variety of quark combinations, two up quarks and one charm quark, for example, or one “strange” quark and two “down” quarks. Because the charm quarks are a particularly heavy variety of quark, scientists should be able to use the new particle to perform different types of tests of their theories of particle interactions.
Although the particle, called a doubly charmed Xi baryon, is the first of its kind, its appearance is no surprise — physicists’ theories predicted its existence. The particle’s mass — about four times that of the proton — agreed with expectations.
Data from a previous experiment had hinted at the presence of a similar doubly charmed particle, but the results were disputed. In 2002, scientists with the SELEX experiment, located at Fermilab in Batavia, Ill., reported that they had discovered a particle composed of two charm quarks and a down quark (SN: 7/6/02, p. 14). But the particle’s properties didn’t align with theoretical expectations, and other experiments couldn’t confirm the results. The new particle further casts doubt on SELEX’s results, because the two baryons should be close in mass, but instead they differ by a significant margin.
Carbon nanotubes may be the key to shrinking down transistors and squeezing more computer power into less space.
Historically, the number of transistors that can be crammed onto a computer chip has doubled every two years or so, a trend known as Moore’s law. But that rule seems to be nearing its limit: Today’s silicon transistors can’t get much smaller than they already are.
Carbon nanotubes may offer a sizable solution. In the June 30 Science, IBM researchers report a carbon-nanotube transistor with an overall width of 40 nanometers — the smallest ever. It’s about half the size of typical silicon transistors.
Researchers have created carbon-nanotube transistors with certain supersmall components before, but the whole package was still bulky, says study coauthor Qing Cao of IBM’s Thomas J. Watson Research Center in Yorktown Heights, N.Y. The new study confirms that, in terms of size, carbon-nanotube transistors can beat out silicon — and that’s no small feat.
Quantum particles can burrow through barriers that should be impenetrable — but they don’t do it instantaneously, a new experiment suggests.
The process, known as quantum tunneling, takes place extremely quickly, making it difficult to confirm whether it takes any time at all. Now, in a study of electrons escaping from their atoms, scientists have pinpointed how long the particles take to tunnel out: around 100 attoseconds, or 100 billionths of a billionth of a second, researchers report July 14 in Physical Review Letters. In quantum tunneling, a particle passes through a barrier despite not having enough energy to cross it. It’s as if someone rolled a ball up a hill but didn’t give it a hard enough push to reach the top, and yet somehow the ball tunneled through to the other side.
Although scientists knew that particles could tunnel, until now, “it was not really clear how that happens, or what, precisely, the particle does,” says physicist Christoph Keitel of the Max Planck Institute for Nuclear Physics in Heidelberg, Germany. Theoretical physicists have long debated between two possible options. In one model, the particle appears immediately on the other side of the barrier, with no initial momentum. In the other, the particle takes time to pass through, and it exits the tunnel with some momentum already built up.
Keitel and colleagues tested quantum tunneling by blasting argon and krypton gas with laser pulses. Normally, the pull of an atom’s positively charged nucleus keeps electrons tightly bound, creating an electromagnetic barrier to their escape. But, given a jolt from a laser, electrons can break free. That jolt weakens the electromagnetic barrier just enough that electrons can leave, but only by tunneling.
Although the scientists weren’t able to measure the tunneling time directly, they set up their experiment so that the angle at which the electrons flew away from the atom would reveal which of the two theories was correct. The laser’s light was circularly polarized — its electromagnetic waves rotated in time, changing the direction of the waves’ wiggles. If the electron escaped immediately, the laser would push it in one particular direction. But if tunneling took time, the laser’s direction would have rotated by the time the electron escaped, so the particle would be pushed in a different direction.
Comparing argon and krypton let the scientists cancel out experimental errors, leading to a more sensitive measurement that was able to distinguish between the two theories. The data matched predictions based on the theory that tunneling takes time. The conclusion jibes with some physicists’ expectations. “I’m pretty sure that the tunneling time cannot be instantaneous, because at the end, in physics, nothing can be instantaneous,” says physicist Ursula Keller of ETH Zurich. The result, she says, agrees with an earlier experiment carried out by her team.
Other scientists still think instantaneous tunneling is possible. Physicist Olga Smirnova of the Max Born Institute in Berlin notes that Keitel and colleagues’ conclusions contradict previous research. In theoretical calculations of tunneling in very simple systems, Smirnova and colleagues found no evidence of tunneling time. The complexity of the atoms studied in the new experiment may have led to the discrepancy, Smirnova says. Still, the experiment is “very accurate and done with great care.”
Although quantum tunneling may seem an esoteric concept, scientists have harnessed it for practical purposes. Scanning tunneling microscopes, for instance, use tunneling electrons to image individual atoms. For such an important fundamental process, Keller says, physicists really have to be certain they understand it. “I don’t think we can close the chapter on the discussion yet,” she says.
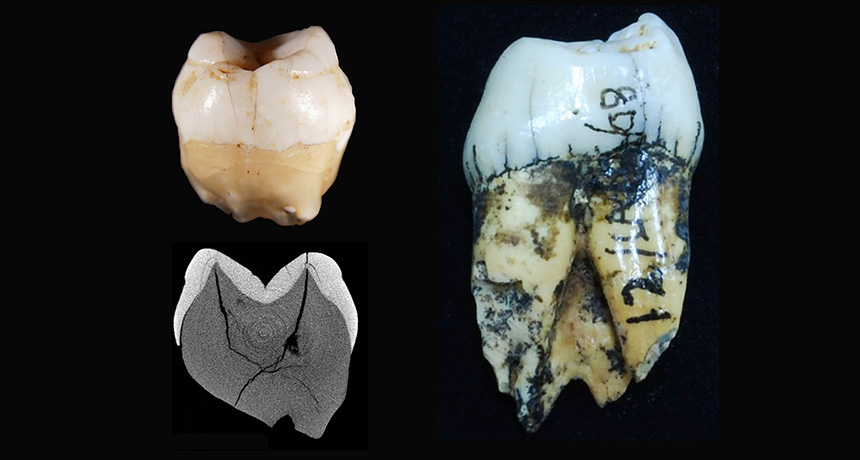
Humans inhabited rainforests on the Indonesian island of Sumatra between 73,000 and 63,000 years ago — shortly before a massive eruption of the island’s Mount Toba volcano covered South Asia in ash, researchers say.
Two teeth previously unearthed in Sumatra’s Lida Ajer cave and assigned to the human genus, Homo, display features typical of Homo sapiens, report geoscientist Kira Westaway of Macquarie University in Sydney and her colleagues. By dating Lida Ajer sediment and formations, the scientists came up with age estimates for the human teeth and associated fossils of various rainforest animals excavated in the late 1800s, including orangutans.
Ancient DNA studies had already suggested that humans from Africa reached Southeast Asian islands before 60,000 years ago.
Humans migrating out of Africa 100,000 years ago or more may have followed coastlines to Southeast Asia and eaten plentiful seafood along the way (SN: 5/19/12, p. 14). But the Sumatran evidence shows that some of the earliest people to depart from Africa figured out how to survive in rainforests, where detailed planning and appropriate tools are needed to gather seasonal plants and hunt scarce, fat-rich prey animals, Westaway and colleagues report online August 9 in Nature.
The sun can’t keep its hands to itself. A constant flow of charged particles streams away from the sun at hundreds of kilometers per second, battering vulnerable planets in its path.
This barrage is called the solar wind, and it has had a direct role in shaping life in the solar system. It’s thought to have stripped away much of Mars’ atmosphere (SN: 4/29/17, p. 20). Earth is protected from a similar fate only by its strong magnetic field, which guides the solar wind around the planet. But scientists don’t understand some key details of how the wind works. It originates in an area where the sun’s surface meets its atmosphere. Like winds on Earth, the solar wind is gusty — it travels at different speeds in different areas. It’s fastest in regions where the sun’s atmosphere, the corona, is dark. Winds whip past these coronal holes at 800 kilometers per second. But the wind whooshes at only around 300 kilometers per second over extended, pointy wisps called coronal streamers, which give the corona its crownlike appearance. No one knows why the wind is fickle. The Aug. 21 solar eclipse gives astronomers an ideal opportunity to catch the solar wind in action in the inner corona. One group, Nat Gopalswamy of NASA’s Goddard Spaceflight Center in Greenbelt, Md., and his colleagues, will test a new version of an instrument called a polarimeter, built to measure the temperature and speed of electrons leaving the sun. Measurements will start close to the sun’s surface and extend out to around 5.6 million kilometers, or eight times the radius of the sun.
“We should be able to detect the baby solar wind,” Gopalswamy says.
Set up at a high school in Madras, Ore., the polarimeter will separate out light that has been polarized, or had its electric field organized in one direction, from light whose electric field oscillates in all sorts of directions. Because electrons scatter polarized light more than non-polarized light, that observation will give the scientists a bead on what the electrons are doing, and by extension, what the solar wind is doing — how fast it flows, how hot it is and even where it comes from. Gopalswamy and colleagues will also take images in four different wavelengths of light, as another measurement of speed and temperature. Mapping the fast and slow solar winds close to the surface of the sun can give clues to how they are accelerated. The team tried out an earlier version of this instrument during an eclipse in 1999 in Turkey. But that instrument required the researchers to flip through three different polarization filters to capture all the information that they wanted. Cycling through the filters using a hand-turned wheel was slow and clunky — a problem when totality, the period when the moon completely blocks the sun, only lasts about two minutes. The team’s upgraded polarimeter is designed so it can simultaneously gather data through all three filters and in four wavelengths of light. “The main requirement is that we have to take these images as close in time as possible, so the corona doesn’t change from one period to the next,” Gopalswamy says. One exposure will take 2 to 4 seconds, plus a 6-second wait between filters. That will give the team about 36 images total.
Gopalswamy and his team first tested this instrument in Indonesia for the March 2016 solar eclipse. “That experiment failed because of noncooperation from nature,” Gopalswamy says. “Ten minutes before the eclipse, the rain started pouring down.”
This year, they chose Madras because, historically, it’s the least cloud-covered place on the eclipse path. But they’re still crossing their fingers for clear skies.
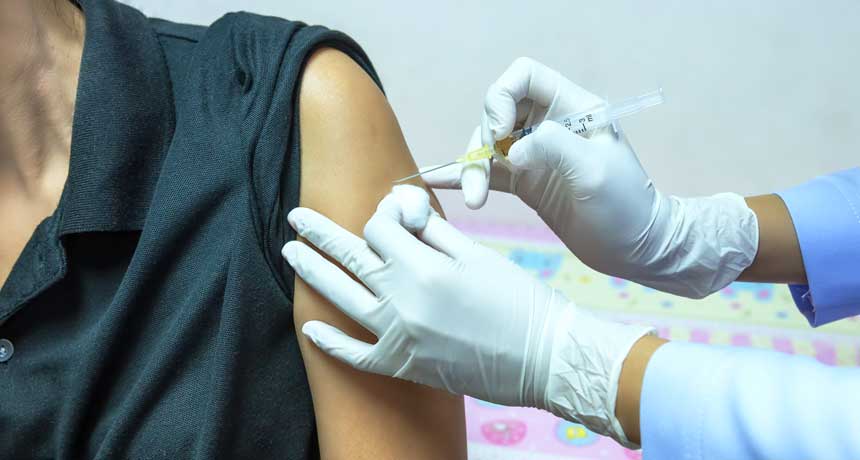
A genetic “crystal ball” can predict whether certain people will respond effectively to the flu vaccine.
Nine genes are associated with a strong immune response to the flu vaccine in those aged 35 and under, a new study finds. If these genes were highly active before vaccination, an individual would generate a high level of antibodies after vaccination, no matter the flu strain in the vaccine, researchers report online August 25 in Science Immunology. This response can help a person avoid getting the flu.
The research team also tried to find a predictive set of genes in people aged 60 and above — a group that includes those more likely to develop serious flu-related complications, such as pneumonia — but failed. Even so, the study is “a step in the right direction,” says Elias Haddad, an immunologist at Drexel University College of Medicine in Philadelphia, who did not participate in the research. “It could have implications in terms of identifying responders versus nonresponders by doing a simple test before a vaccination.”
The U.S. Centers for Disease Control and Prevention estimates that vaccination prevented 5.1 million flu illnesses in the 2015‒2016 season. Getting a flu shot is the best way to stay healthy, but “the problem is, we don’t know what makes a successful vaccination,” says Purvesh Khatri, a computational immunologist at Stanford University School of Medicine. “The immune system is very personal.” Khatri and colleagues wondered if there was a certain immune state one needed to be in to respond effectively to the flu vaccine. So the researchers looked for a common genetic signal in blood samples from 175 people with different genetic backgrounds, from different locations in the United States, and who received the flu vaccine in different seasons. After identifying the set of predictive genes, the team used another collection of 82 samples to confirm that the crystal ball accurately predicted a strong flu response. Using such a variety of samples makes it more likely that the crystal ball will work for many different people in the real world, Khatri says.
The nine genes make proteins that have various jobs, including directing the movement of other proteins and providing structure to cells. Previous research on these genes has tied some of them to the immune system, but not others. Khatri expects the study will spur investigations into how the genes promote a successful vaccine response. And figuring out how to boost the genes may help those who don’t respond strongly to flu vaccine, he says.
As for finding a genetic crystal ball for older adults, “there’s still hope that we’ll be able to,” says team member Raphael Gottardo, a computational biologist at the Fred Hutchinson Cancer Research Center in Seattle. Older people are even more diverse in how they respond to the flu vaccine than younger people, he says, so it may take a larger group of samples to find a common genetic thread.
More research is also needed to learn whether the identified genes will predict an effective response for all vaccines, or just the flu, Haddad says. “There is a long way to go here.”
You’ve probably encountered at least one machine-learning algorithm today. These clever computer codes sort search engine results, weed spam e-mails from inboxes and optimize navigation routes in real time. People entrust these programs with increasingly complex — and sometimes life-changing — decisions, such as diagnosing diseases and predicting criminal activity.
Machine-learning algorithms can make these sophisticated calls because they don’t simply follow a series of programmed instructions the way traditional algorithms do. Instead, these souped-up programs study past examples of how to complete a task, discern patterns from the examples and use that information to make decisions on a case-by-case basis. Unfortunately, letting machines with this artificial intelligence, or AI, figure things out for themselves doesn’t just make them good critical “thinkers,” it also gives them a chance to pick up biases.
Investigations in recent years have uncovered several ways algorithms exhibit discrimination. In 2015, researchers reported that Google’s ad service preferentially displayed postings related to high-paying jobs to men. A 2016 ProPublica investigation found that COMPAS, a tool used by many courtrooms to predict whether a criminal will break the law again, wrongly predicted that black defendants would reoffend nearly twice as often as it made that wrong prediction for whites. The Human Rights Data Analysis Group also showed that the crime prediction tool PredPol could lead police to unfairly target low-income, minority neighborhoods (SN Online: 3/8/17). Clearly, algorithms’ seemingly humanlike intelligence can come with humanlike prejudices.
“This is a very common issue with machine learning,” says computer scientist Moritz Hardt of the University of California, Berkeley. Even if a programmer designs an algorithm without prejudicial intent, “you’re very likely to end up in a situation that will have fairness issues,” Hardt says. “This is more the default than the exception.” Developers may not even realize a program has taught itself certain prejudices. This problem gets down to what is known as a black box issue: How exactly is an algorithm reaching its conclusions? Since no one tells a machine-learning algorithm exactly how to do its job, it’s often unclear — even to the algorithm’s creator — how or why it ends up using data the way it does to make decisions. Several socially conscious computer and data scientists have recently started wrestling with the problem of machine bias. Some have come up with ways to add fairness requirements into machine-learning systems. Others have found ways to illuminate the sources of algorithms’ biased behavior. But the very nature of machine-learning algorithms as self-taught systems means there’s no easy fix to make them play fair.
Learning by example In most cases, machine learning is a game of algorithm see, algorithm do. The programmer assigns an algorithm a goal — say, predicting whether people will default on loans. But the machine gets no explicit instructions on how to achieve that goal. Instead, the programmer gives the algorithm a dataset to learn from, such as a cache of past loan applications labeled with whether the applicant defaulted.
The algorithm then tests various ways to combine loan application attributes to predict who will default. The program works through all of the applications in the dataset, fine-tuning its decision-making procedure along the way. Once fully trained, the algorithm should ideally be able to take any new loan application and accurately determine whether that person will default.
The trouble arises when training data are riddled with biases that an algorithm may incorporate into its decisions. For instance, if a human resources department’s hiring algorithm is trained on historical employment data from a time when men were favored over women, it may recommend hiring men more often than women. Or, if there were fewer female applicants in the past, then the algorithm has fewer examples of those applications to learn from, and it may not be as accurate at judging women’s applications. At first glance, the answer seems obvious: Remove any sensitive features, such as race or sex, from the training data. The problem is, there are many ostensibly nonsensitive aspects of a dataset that could play proxy for some sensitive feature. Zip code may be strongly related to race, college major to sex, health to socioeconomic status.
And it may be impossible to tell how different pieces of data — sensitive or otherwise — factor into an algorithm’s verdicts. Many machine-learning algorithms develop deliberative processes that involve so many thousands of complex steps that they’re impossible for people to review.
Creators of machine-learning systems “used to be able to look at the source code of our programs and understand how they work, but that era is long gone,” says Simon DeDeo, a cognitive scientist at Carnegie Mellon University in Pittsburgh. In many cases, neither an algorithm’s authors nor its users care how it works, as long as it works, he adds. “It’s like, ‘I don’t care how you made the food; it tastes good.’ ”
But in other cases, the inner workings of an algorithm could make the difference between someone getting parole, an executive position, a mortgage or even a scholarship. So computer and data scientists are coming up with creative ways to work around the black box status of machine-learning algorithms.
Setting algorithms straight Some researchers have suggested that training data could be edited before given to machine-learning programs so that the data are less likely to imbue algorithms with bias. In 2015, one group proposed testing data for potential bias by building a computer program that uses people’s nonsensitive features to predict their sensitive ones, like race or sex. If the program could do this with reasonable accuracy, the dataset’s sensitive and nonsensitive attributes were tightly connected, the researchers concluded. That tight connection was liable to train discriminatory machine-learning algorithms.
To fix bias-prone datasets, the scientists proposed altering the values of whatever nonsensitive elements their computer program had used to predict sensitive features. For instance, if their program had relied heavily on zip code to predict race, the researchers could assign fake values to more and more digits of people’s zip codes until they were no longer a useful predictor for race. The data could be used to train an algorithm clear of that bias — though there might be a tradeoff with accuracy.
On the flip side, other research groups have proposed de-biasing the outputs of already-trained machine-learning algorithms. In 2016 at the Conference on Neural Information Processing Systems in Barcelona, Hardt and colleagues recommended comparing a machine-learning algorithm’s past predictions with real-world outcomes to see if the algorithm was making mistakes equally for different demographics. This was meant to prevent situations like the one created by COMPAS, which made wrong predictions about black and white defendants at different rates. Among defendants who didn’t go on to commit more crimes, blacks were flagged by COMPAS as future criminals more often than whites. Among those who did break the law again, whites were more often mislabeled as low-risk for future criminal activity.
For a machine-learning algorithm that exhibits this kind of discrimination, Hardt’s team suggested switching some of the program’s past decisions until each demographic gets erroneous outputs at the same rate. Then, that amount of output muddling, a sort of correction, could be applied to future verdicts to ensure continued even-handedness. One limitation, Hardt points out, is that it may take a while to collect a sufficient stockpile of actual outcomes to compare with the algorithm’s predictions. A third camp of researchers has written fairness guidelines into the machine-learning algorithms themselves. The idea is that when people let an algorithm loose on a training dataset, they don’t just give the software the goal of making accurate decisions. The programmers also tell the algorithm that its outputs must meet some certain standard of fairness, so it should design its decision-making procedure accordingly.
In April, computer scientist Bilal Zafar of the Max Planck Institute for Software Systems in Kaiserslautern, Germany, and colleagues proposed that developers add instructions to machine-learning algorithms to ensure they dole out errors to different demographics at equal rates — the same type of requirement Hardt’s team set. This technique, presented in Perth, Australia, at the International World Wide Web Conference, requires that the training data have information about whether the examples in the dataset were actually good or bad decisions. For something like stop-and-frisk data, where it’s known whether a frisked person actually had a weapon, the approach works. Developers could add code to their program that tells it to account for past wrongful stops.
Zafar and colleagues tested their technique by designing a crime-predicting machine-learning algorithm with specific nondiscrimination instructions. The researchers trained their algorithm on a dataset containing criminal profiles and whether those people actually reoffended. By forcing their algorithm to be a more equal opportunity error-maker, the researchers were able to reduce the difference between how often blacks and whites who didn’t recommit were wrongly classified as being likely to do so: The fraction of people that COMPAS mislabeled as future criminals was about 45 percent for blacks and 23 percent for whites. In the researchers’ new algorithm, misclassification of blacks dropped to 26 percent and held at 23 percent for whites.
These are just a few recent additions to a small, but expanding, toolbox of techniques for forcing fairness on machine-learning systems. But how these algorithmic fix-its stack up against one another is an open question since many of them use different standards of fairness. Some require algorithms to give members of different populations certain results at about the same rate. Others tell an algorithm to accurately classify or misclassify different groups at the same rate. Still others work with definitions of individual fairness that require algorithms to treat people who are similar barring one sensitive feature similarly. To complicate matters, recent research has shown that, in some cases, meeting more than one fairness criterion at once can be impossible.
“We have to think about forms of unfairness that we may want to eliminate, rather than hoping for a system that is absolutely fair in every possible dimension,” says Anupam Datta, a computer scientist at Carnegie Mellon.
Still, those who don’t want to commit to one standard of fairness can perform de-biasing procedures after the fact to see whether outputs change, Hardt says, which could be a warning sign of algorithmic bias.
Show your work But even if someone discovered that an algorithm fell short of some fairness standard, that wouldn’t necessarily mean the program needed to be changed, Datta says. He imagines a scenario in which a credit-classifying algorithm might give favorable results to some races more than others. If the algorithm based its decisions on race or some race-related variable like zip code that shouldn’t affect credit scoring, that would be a problem. But what if the algorithm’s scores relied heavily on debt-to-income ratio, which may also be associated with race? “We may want to allow that,” Datta says, since debt-to-income ratio is a feature directly relevant to credit.
Of course, users can’t easily judge an algorithm’s fairness on these finer points when its reasoning is a total black box. So computer scientists have to find indirect ways to discern what machine-learning systems are up to.
One technique for interrogating algorithms, proposed by Datta and colleagues in 2016 in San Jose, Calif., at the IEEE Symposium on Security and Privacy, involves altering the inputs of an algorithm and observing how that affects the outputs. “Let’s say I’m interested in understanding the influence of my age on this decision, or my gender on this decision,” Datta says. “Then I might be interested in asking, ‘What if I had a clone that was identical to me, but the gender was flipped? Would the outcome be different or not?’ ” In this way, the researchers could determine how much individual features or groups of features affect an algorithm’s judgments. Users performing this kind of auditing could decide for themselves whether the algorithm’s use of data was cause for concern. Of course, if the code’s behavior is deemed unacceptable, there’s still the question of what to do about it. There’s no “So your algorithm is biased, now what?” instruction manual. The effort to curb machine bias is still in its nascent stages. “I’m not aware of any system either identifying or resolving discrimination that’s actively deployed in any application,” says Nathan Srebro, a computer scientist at the University of Chicago. “Right now, it’s mostly trying to figure things out.”
Computer scientist Suresh Venkatasubramanian agrees. “Every research area has to go through this exploration phase,” he says, “where we may have only very preliminary and half-baked answers, but the questions are interesting.”
Still, Venkatasubramanian, of the University of Utah in Salt Lake City, is optimistic about the future of this important corner of computer and data science. “For a couple of years now … the cadence of the debate has gone something like this: ‘Algorithms are awesome, we should use them everywhere. Oh no, algorithms are not awesome, here are their problems,’ ” he says. But now, at least, people have started proposing solutions, and weighing the various benefits and limitations of those ideas. So, he says, “we’re not freaking out as much.”
Here are the final images from Cassini’s last look around the Saturn system.
In its last hours before plunging into Saturn’s atmosphere, the Cassini spacecraft turned its cameras to the mission team’s favorite objects: the hydrocarbon-shrouded moon Titan, the geyser moon Enceladus and, of course, the majestic rings.
After sending these raw images back to Earth, Cassini reconfigured itself to stream data efficiently in near–real time. Image files are too big to send in this mode, so these are the last pictures Cassini will ever show us. But it will send back unprecedented information about Saturn’s atmosphere right up until the end.
The tiny moon Enceladus, which has a liquid sea below its icy surface and spews geysers of water into space, set behind Saturn as Cassini watched: Saturn looms large in this Sept. 14 raw image from the Cassini spacecraft: The hazy moon Titan is the largest in the Saturn system. Its gravity nudged Cassini onto its doomed orbit when the spacecraft flew by on September 11:
It’s hard not to compliment kids on certain things. When my little girls fancy themselves up in tutus, which is every single time we leave the house, people tell them how pretty they are. I know these folks’ intentions are good, but an abundance of compliments on clothes and looks sends messages I’d rather my girls didn’t absorb at ages 2 and 4. Or ever, for that matter.
Our words, often spoken casually and without much thought, can have a big influence on little kids’ views of themselves and their behaviors. That’s very clear from two new studies on children who were praised for being smart.
The studies, conducted in China on children ages 3 and 5, suggest that directly telling kids they’re smart, or that other people think they’re intelligent, makes them more likely to cheat to win a game.
In the first study, published September 12 in Psychological Science, 150 3-year-olds and 150 5-year-olds played a card guessing game. An experimenter hid a card behind a barrier and the children had to guess whether the card’s number was greater or less than six. In some early rounds of the game, a researcher told some of the children, “You are so smart.” Others were told, “You did very well this time.” Still others weren’t praised at all.
Just before the kids guessed the final card in the game, the experimenter left the room, but not before reminding the children not to peek. A video camera monitored the kids as they sat alone.
The children who had been praised for being smart were more likely to peek, either by walking around or leaning over the barrier, than the children in the other two groups, the researchers found. Among 3-year-olds who had been praised for their ability (“You did very well this time.”) or not praised at all, about 40 percent cheated. But the share of cheaters jumped to about 60 percent among the 3-year-olds who had been praised as smart. Similar, but slightly lower, numbers were seen for the 5-year-olds.
In another paper, published July 12 in Developmental Science, the same group of researchers tested whether having a reputation for smarts would have an effect on cheating. At the beginning of a similar card game played with 3- and 5-year-old Chinese children, researchers told some of the kids that they had a reputation for being smart. Other kids were told they had a reputation for cleanliness, while a third group was told nothing about their reputation. The same phenomenon emerged: Kids told they had a reputation for smarts were more likely than the other children to peek at the cards. The kids who cheated probably felt more pressure to live up to their smart reputation, and that pressure may promote winning at any cost, says study coauthor Gail Heyman. She’s a psychologist at the University of California, San Diego and a visiting professor at Zhejiang Normal University in Jinhua, China. Other issues might be at play, too, she says, “such as giving children a feeling of superiority that gives them a sense that they are above the rules.”
Previous research has suggested that praising kids for their smarts can backfire in a different way: It might sap their motivation and performance.
Heyman was surprised to see that children as young as 3 shifted their behavior based on the researchers’ comments. “I didn’t think it was worth testing children this age, who have such a vague understanding of what it means to be smart,” she says. But even in these young children, words seemed to have a powerful effect.
The results, and other similar work, suggest that parents might want to curb the impulse to tell their children how smart they are. Instead, Heyman suggests, keep praise specific: “You did a nice job on the project,” or “I like the solution you came up with.” Likewise, comments that focus on the process are good choices: “How did you figure that out?” and “Isn’t it fun to struggle with a hard problem like that?”
It’s unrealistic to expect parents — and everyone else who comes into contact with children — to always come up with the “right” compliment. But I do think it’s worth paying attention to the way we talk with our kids, and what we want them to learn about themselves. These studies have been a good reminder for me that comments made to my kids — by anyone — matter, perhaps more than I know.