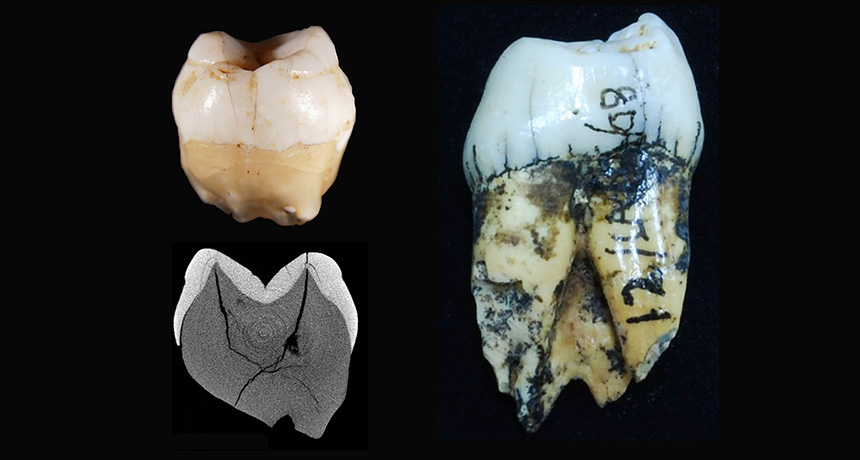
Humans inhabited rainforests on the Indonesian island of Sumatra between 73,000 and 63,000 years ago — shortly before a massive eruption of the island’s Mount Toba volcano covered South Asia in ash, researchers say.
Two teeth previously unearthed in Sumatra’s Lida Ajer cave and assigned to the human genus, Homo, display features typical of Homo sapiens, report geoscientist Kira Westaway of Macquarie University in Sydney and her colleagues. By dating Lida Ajer sediment and formations, the scientists came up with age estimates for the human teeth and associated fossils of various rainforest animals excavated in the late 1800s, including orangutans.
Ancient DNA studies had already suggested that humans from Africa reached Southeast Asian islands before 60,000 years ago.
Humans migrating out of Africa 100,000 years ago or more may have followed coastlines to Southeast Asia and eaten plentiful seafood along the way (SN: 5/19/12, p. 14). But the Sumatran evidence shows that some of the earliest people to depart from Africa figured out how to survive in rainforests, where detailed planning and appropriate tools are needed to gather seasonal plants and hunt scarce, fat-rich prey animals, Westaway and colleagues report online August 9 in Nature.
The sun can’t keep its hands to itself. A constant flow of charged particles streams away from the sun at hundreds of kilometers per second, battering vulnerable planets in its path.
This barrage is called the solar wind, and it has had a direct role in shaping life in the solar system. It’s thought to have stripped away much of Mars’ atmosphere (SN: 4/29/17, p. 20). Earth is protected from a similar fate only by its strong magnetic field, which guides the solar wind around the planet. But scientists don’t understand some key details of how the wind works. It originates in an area where the sun’s surface meets its atmosphere. Like winds on Earth, the solar wind is gusty — it travels at different speeds in different areas. It’s fastest in regions where the sun’s atmosphere, the corona, is dark. Winds whip past these coronal holes at 800 kilometers per second. But the wind whooshes at only around 300 kilometers per second over extended, pointy wisps called coronal streamers, which give the corona its crownlike appearance. No one knows why the wind is fickle. The Aug. 21 solar eclipse gives astronomers an ideal opportunity to catch the solar wind in action in the inner corona. One group, Nat Gopalswamy of NASA’s Goddard Spaceflight Center in Greenbelt, Md., and his colleagues, will test a new version of an instrument called a polarimeter, built to measure the temperature and speed of electrons leaving the sun. Measurements will start close to the sun’s surface and extend out to around 5.6 million kilometers, or eight times the radius of the sun.
“We should be able to detect the baby solar wind,” Gopalswamy says.
Set up at a high school in Madras, Ore., the polarimeter will separate out light that has been polarized, or had its electric field organized in one direction, from light whose electric field oscillates in all sorts of directions. Because electrons scatter polarized light more than non-polarized light, that observation will give the scientists a bead on what the electrons are doing, and by extension, what the solar wind is doing — how fast it flows, how hot it is and even where it comes from. Gopalswamy and colleagues will also take images in four different wavelengths of light, as another measurement of speed and temperature. Mapping the fast and slow solar winds close to the surface of the sun can give clues to how they are accelerated. The team tried out an earlier version of this instrument during an eclipse in 1999 in Turkey. But that instrument required the researchers to flip through three different polarization filters to capture all the information that they wanted. Cycling through the filters using a hand-turned wheel was slow and clunky — a problem when totality, the period when the moon completely blocks the sun, only lasts about two minutes. The team’s upgraded polarimeter is designed so it can simultaneously gather data through all three filters and in four wavelengths of light. “The main requirement is that we have to take these images as close in time as possible, so the corona doesn’t change from one period to the next,” Gopalswamy says. One exposure will take 2 to 4 seconds, plus a 6-second wait between filters. That will give the team about 36 images total.
Gopalswamy and his team first tested this instrument in Indonesia for the March 2016 solar eclipse. “That experiment failed because of noncooperation from nature,” Gopalswamy says. “Ten minutes before the eclipse, the rain started pouring down.”
This year, they chose Madras because, historically, it’s the least cloud-covered place on the eclipse path. But they’re still crossing their fingers for clear skies.
A genetic “crystal ball” can predict whether certain people will respond effectively to the flu vaccine.
Nine genes are associated with a strong immune response to the flu vaccine in those aged 35 and under, a new study finds. If these genes were highly active before vaccination, an individual would generate a high level of antibodies after vaccination, no matter the flu strain in the vaccine, researchers report online August 25 in Science Immunology. This response can help a person avoid getting the flu.
The research team also tried to find a predictive set of genes in people aged 60 and above — a group that includes those more likely to develop serious flu-related complications, such as pneumonia — but failed. Even so, the study is “a step in the right direction,” says Elias Haddad, an immunologist at Drexel University College of Medicine in Philadelphia, who did not participate in the research. “It could have implications in terms of identifying responders versus nonresponders by doing a simple test before a vaccination.”
The U.S. Centers for Disease Control and Prevention estimates that vaccination prevented 5.1 million flu illnesses in the 2015‒2016 season. Getting a flu shot is the best way to stay healthy, but “the problem is, we don’t know what makes a successful vaccination,” says Purvesh Khatri, a computational immunologist at Stanford University School of Medicine. “The immune system is very personal.” Khatri and colleagues wondered if there was a certain immune state one needed to be in to respond effectively to the flu vaccine. So the researchers looked for a common genetic signal in blood samples from 175 people with different genetic backgrounds, from different locations in the United States, and who received the flu vaccine in different seasons. After identifying the set of predictive genes, the team used another collection of 82 samples to confirm that the crystal ball accurately predicted a strong flu response. Using such a variety of samples makes it more likely that the crystal ball will work for many different people in the real world, Khatri says.
The nine genes make proteins that have various jobs, including directing the movement of other proteins and providing structure to cells. Previous research on these genes has tied some of them to the immune system, but not others. Khatri expects the study will spur investigations into how the genes promote a successful vaccine response. And figuring out how to boost the genes may help those who don’t respond strongly to flu vaccine, he says.
As for finding a genetic crystal ball for older adults, “there’s still hope that we’ll be able to,” says team member Raphael Gottardo, a computational biologist at the Fred Hutchinson Cancer Research Center in Seattle. Older people are even more diverse in how they respond to the flu vaccine than younger people, he says, so it may take a larger group of samples to find a common genetic thread.
More research is also needed to learn whether the identified genes will predict an effective response for all vaccines, or just the flu, Haddad says. “There is a long way to go here.”
You’ve probably encountered at least one machine-learning algorithm today. These clever computer codes sort search engine results, weed spam e-mails from inboxes and optimize navigation routes in real time. People entrust these programs with increasingly complex — and sometimes life-changing — decisions, such as diagnosing diseases and predicting criminal activity.
Machine-learning algorithms can make these sophisticated calls because they don’t simply follow a series of programmed instructions the way traditional algorithms do. Instead, these souped-up programs study past examples of how to complete a task, discern patterns from the examples and use that information to make decisions on a case-by-case basis. Unfortunately, letting machines with this artificial intelligence, or AI, figure things out for themselves doesn’t just make them good critical “thinkers,” it also gives them a chance to pick up biases.
Investigations in recent years have uncovered several ways algorithms exhibit discrimination. In 2015, researchers reported that Google’s ad service preferentially displayed postings related to high-paying jobs to men. A 2016 ProPublica investigation found that COMPAS, a tool used by many courtrooms to predict whether a criminal will break the law again, wrongly predicted that black defendants would reoffend nearly twice as often as it made that wrong prediction for whites. The Human Rights Data Analysis Group also showed that the crime prediction tool PredPol could lead police to unfairly target low-income, minority neighborhoods (SN Online: 3/8/17). Clearly, algorithms’ seemingly humanlike intelligence can come with humanlike prejudices.
“This is a very common issue with machine learning,” says computer scientist Moritz Hardt of the University of California, Berkeley. Even if a programmer designs an algorithm without prejudicial intent, “you’re very likely to end up in a situation that will have fairness issues,” Hardt says. “This is more the default than the exception.” Developers may not even realize a program has taught itself certain prejudices. This problem gets down to what is known as a black box issue: How exactly is an algorithm reaching its conclusions? Since no one tells a machine-learning algorithm exactly how to do its job, it’s often unclear — even to the algorithm’s creator — how or why it ends up using data the way it does to make decisions. Several socially conscious computer and data scientists have recently started wrestling with the problem of machine bias. Some have come up with ways to add fairness requirements into machine-learning systems. Others have found ways to illuminate the sources of algorithms’ biased behavior. But the very nature of machine-learning algorithms as self-taught systems means there’s no easy fix to make them play fair.
Learning by example In most cases, machine learning is a game of algorithm see, algorithm do. The programmer assigns an algorithm a goal — say, predicting whether people will default on loans. But the machine gets no explicit instructions on how to achieve that goal. Instead, the programmer gives the algorithm a dataset to learn from, such as a cache of past loan applications labeled with whether the applicant defaulted.
The algorithm then tests various ways to combine loan application attributes to predict who will default. The program works through all of the applications in the dataset, fine-tuning its decision-making procedure along the way. Once fully trained, the algorithm should ideally be able to take any new loan application and accurately determine whether that person will default.
The trouble arises when training data are riddled with biases that an algorithm may incorporate into its decisions. For instance, if a human resources department’s hiring algorithm is trained on historical employment data from a time when men were favored over women, it may recommend hiring men more often than women. Or, if there were fewer female applicants in the past, then the algorithm has fewer examples of those applications to learn from, and it may not be as accurate at judging women’s applications. At first glance, the answer seems obvious: Remove any sensitive features, such as race or sex, from the training data. The problem is, there are many ostensibly nonsensitive aspects of a dataset that could play proxy for some sensitive feature. Zip code may be strongly related to race, college major to sex, health to socioeconomic status.
And it may be impossible to tell how different pieces of data — sensitive or otherwise — factor into an algorithm’s verdicts. Many machine-learning algorithms develop deliberative processes that involve so many thousands of complex steps that they’re impossible for people to review.
Creators of machine-learning systems “used to be able to look at the source code of our programs and understand how they work, but that era is long gone,” says Simon DeDeo, a cognitive scientist at Carnegie Mellon University in Pittsburgh. In many cases, neither an algorithm’s authors nor its users care how it works, as long as it works, he adds. “It’s like, ‘I don’t care how you made the food; it tastes good.’ ”
But in other cases, the inner workings of an algorithm could make the difference between someone getting parole, an executive position, a mortgage or even a scholarship. So computer and data scientists are coming up with creative ways to work around the black box status of machine-learning algorithms.
Setting algorithms straight Some researchers have suggested that training data could be edited before given to machine-learning programs so that the data are less likely to imbue algorithms with bias. In 2015, one group proposed testing data for potential bias by building a computer program that uses people’s nonsensitive features to predict their sensitive ones, like race or sex. If the program could do this with reasonable accuracy, the dataset’s sensitive and nonsensitive attributes were tightly connected, the researchers concluded. That tight connection was liable to train discriminatory machine-learning algorithms.
To fix bias-prone datasets, the scientists proposed altering the values of whatever nonsensitive elements their computer program had used to predict sensitive features. For instance, if their program had relied heavily on zip code to predict race, the researchers could assign fake values to more and more digits of people’s zip codes until they were no longer a useful predictor for race. The data could be used to train an algorithm clear of that bias — though there might be a tradeoff with accuracy.
On the flip side, other research groups have proposed de-biasing the outputs of already-trained machine-learning algorithms. In 2016 at the Conference on Neural Information Processing Systems in Barcelona, Hardt and colleagues recommended comparing a machine-learning algorithm’s past predictions with real-world outcomes to see if the algorithm was making mistakes equally for different demographics. This was meant to prevent situations like the one created by COMPAS, which made wrong predictions about black and white defendants at different rates. Among defendants who didn’t go on to commit more crimes, blacks were flagged by COMPAS as future criminals more often than whites. Among those who did break the law again, whites were more often mislabeled as low-risk for future criminal activity.
For a machine-learning algorithm that exhibits this kind of discrimination, Hardt’s team suggested switching some of the program’s past decisions until each demographic gets erroneous outputs at the same rate. Then, that amount of output muddling, a sort of correction, could be applied to future verdicts to ensure continued even-handedness. One limitation, Hardt points out, is that it may take a while to collect a sufficient stockpile of actual outcomes to compare with the algorithm’s predictions. A third camp of researchers has written fairness guidelines into the machine-learning algorithms themselves. The idea is that when people let an algorithm loose on a training dataset, they don’t just give the software the goal of making accurate decisions. The programmers also tell the algorithm that its outputs must meet some certain standard of fairness, so it should design its decision-making procedure accordingly.
In April, computer scientist Bilal Zafar of the Max Planck Institute for Software Systems in Kaiserslautern, Germany, and colleagues proposed that developers add instructions to machine-learning algorithms to ensure they dole out errors to different demographics at equal rates — the same type of requirement Hardt’s team set. This technique, presented in Perth, Australia, at the International World Wide Web Conference, requires that the training data have information about whether the examples in the dataset were actually good or bad decisions. For something like stop-and-frisk data, where it’s known whether a frisked person actually had a weapon, the approach works. Developers could add code to their program that tells it to account for past wrongful stops.
Zafar and colleagues tested their technique by designing a crime-predicting machine-learning algorithm with specific nondiscrimination instructions. The researchers trained their algorithm on a dataset containing criminal profiles and whether those people actually reoffended. By forcing their algorithm to be a more equal opportunity error-maker, the researchers were able to reduce the difference between how often blacks and whites who didn’t recommit were wrongly classified as being likely to do so: The fraction of people that COMPAS mislabeled as future criminals was about 45 percent for blacks and 23 percent for whites. In the researchers’ new algorithm, misclassification of blacks dropped to 26 percent and held at 23 percent for whites.
These are just a few recent additions to a small, but expanding, toolbox of techniques for forcing fairness on machine-learning systems. But how these algorithmic fix-its stack up against one another is an open question since many of them use different standards of fairness. Some require algorithms to give members of different populations certain results at about the same rate. Others tell an algorithm to accurately classify or misclassify different groups at the same rate. Still others work with definitions of individual fairness that require algorithms to treat people who are similar barring one sensitive feature similarly. To complicate matters, recent research has shown that, in some cases, meeting more than one fairness criterion at once can be impossible.
“We have to think about forms of unfairness that we may want to eliminate, rather than hoping for a system that is absolutely fair in every possible dimension,” says Anupam Datta, a computer scientist at Carnegie Mellon.
Still, those who don’t want to commit to one standard of fairness can perform de-biasing procedures after the fact to see whether outputs change, Hardt says, which could be a warning sign of algorithmic bias.
Show your work But even if someone discovered that an algorithm fell short of some fairness standard, that wouldn’t necessarily mean the program needed to be changed, Datta says. He imagines a scenario in which a credit-classifying algorithm might give favorable results to some races more than others. If the algorithm based its decisions on race or some race-related variable like zip code that shouldn’t affect credit scoring, that would be a problem. But what if the algorithm’s scores relied heavily on debt-to-income ratio, which may also be associated with race? “We may want to allow that,” Datta says, since debt-to-income ratio is a feature directly relevant to credit.
Of course, users can’t easily judge an algorithm’s fairness on these finer points when its reasoning is a total black box. So computer scientists have to find indirect ways to discern what machine-learning systems are up to.
One technique for interrogating algorithms, proposed by Datta and colleagues in 2016 in San Jose, Calif., at the IEEE Symposium on Security and Privacy, involves altering the inputs of an algorithm and observing how that affects the outputs. “Let’s say I’m interested in understanding the influence of my age on this decision, or my gender on this decision,” Datta says. “Then I might be interested in asking, ‘What if I had a clone that was identical to me, but the gender was flipped? Would the outcome be different or not?’ ” In this way, the researchers could determine how much individual features or groups of features affect an algorithm’s judgments. Users performing this kind of auditing could decide for themselves whether the algorithm’s use of data was cause for concern. Of course, if the code’s behavior is deemed unacceptable, there’s still the question of what to do about it. There’s no “So your algorithm is biased, now what?” instruction manual. The effort to curb machine bias is still in its nascent stages. “I’m not aware of any system either identifying or resolving discrimination that’s actively deployed in any application,” says Nathan Srebro, a computer scientist at the University of Chicago. “Right now, it’s mostly trying to figure things out.”
Computer scientist Suresh Venkatasubramanian agrees. “Every research area has to go through this exploration phase,” he says, “where we may have only very preliminary and half-baked answers, but the questions are interesting.”
Still, Venkatasubramanian, of the University of Utah in Salt Lake City, is optimistic about the future of this important corner of computer and data science. “For a couple of years now … the cadence of the debate has gone something like this: ‘Algorithms are awesome, we should use them everywhere. Oh no, algorithms are not awesome, here are their problems,’ ” he says. But now, at least, people have started proposing solutions, and weighing the various benefits and limitations of those ideas. So, he says, “we’re not freaking out as much.”
Here are the final images from Cassini’s last look around the Saturn system.
In its last hours before plunging into Saturn’s atmosphere, the Cassini spacecraft turned its cameras to the mission team’s favorite objects: the hydrocarbon-shrouded moon Titan, the geyser moon Enceladus and, of course, the majestic rings.
After sending these raw images back to Earth, Cassini reconfigured itself to stream data efficiently in near–real time. Image files are too big to send in this mode, so these are the last pictures Cassini will ever show us. But it will send back unprecedented information about Saturn’s atmosphere right up until the end.
The tiny moon Enceladus, which has a liquid sea below its icy surface and spews geysers of water into space, set behind Saturn as Cassini watched: Saturn looms large in this Sept. 14 raw image from the Cassini spacecraft: The hazy moon Titan is the largest in the Saturn system. Its gravity nudged Cassini onto its doomed orbit when the spacecraft flew by on September 11:
Discoveries about the molecular ups and downs of fruit flies’ daily lives have won Jeffrey C. Hall, Michael Rosbash and Michael W. Young the Nobel Prize in physiology or medicine.
These three Americans were honored October 2 by the Nobel Assembly at the Karolinska Institute in Stockholm for their work in discovering important gears in the circadian clocks of animals. The trio will equally split the 9 million Swedish kronor prize — each taking home the equivalent of $367,000. The researchers did their work in fruit flies. But “an awful lot of what was subsequently found out in the fruit flies turns out also to be true and of huge relevance to humans,” says John O’Neill, a circadian cell biologist at the MRC Laboratory of Molecular Biology in Cambridge, England. Mammals, humans included, have circadian clocks that work with the same logic and many of the same gears found in fruit flies, say Jennifer Loros and Jay Dunlap, geneticists at the Geisel School of Medicine at Dartmouth College. Circadian clocks are networks of genes and proteins that govern daily rhythms and cycles such as sleep, the release of hormones, the rise and fall of body temperature and blood pressure, as well as other body processes. Circadian rhythms help organisms, including humans, anticipate and adapt to cyclic changes of light, dark and temperature caused by Earth’s rotation. When circadian rhythms are thrown out of whack, jet lag results. Shift workers and people with chronic sleep deprivation experience long-term jet lag that has been linked to serious health consequences including cancer, diabetes, heart disease, obesity and depression. Before the laureates did their work, other scientists had established that plants and animals have circadian rhythms. In 1971, Seymour Benzer and Ronald Konopka (both now deceased and ineligible for the Nobel Prize) found that fruit flies with mutations in a single gene called period had disrupted circadian rhythms, which caused the flies to move around at different times of day than normal.
“But then people got stuck,” says chronobiologist Erik Herzog of Washington University in St. Louis. “We couldn’t figure out what that gene was or how that gene worked.” At Brandeis University in Waltham, Mass., Hall, a geneticist, teamed up with molecular biologist Rosbash to identify the period gene at the molecular level in 1984. Young of the Rockefeller University in New York City simultaneously deciphered the gene’s DNA makeup. “In the beginning, we didn’t even know the other group was working on it, until we all showed up at a conference together and discovered we were working on the same thing,” says Young. “We said, ‘Well, let’s forge ahead. Best of luck.’” It wasn’t immediately apparent how the gene regulated fruit fly activity. In 1990, Hall and Rosbash determined that levels of period’s messenger RNA — an intermediate step between DNA and protein — fell as levels of period’s protein, called PER, rose. That finding indicated that PER protein shuts down its own gene’s activity.
A clock, however, isn’t composed of just one gear, Young says. He discovered in 1994 another gene called timeless. That gene’s protein, called TIM, works with PER to drive the clock. Young also discovered other circadian clockworks, including doubletime and its protein DBT, which set the clock’s pace. Rosbash and Hall discovered yet more gears and the two groups competed and collaborated with each other. “This whole thing would not have turned out nearly as nicely if we’d been the only ones working on it, or they had,” Young says.
Since those discoveries, researchers have found that nearly every cell in the body contains a circadian clock, and almost every gene follows circadian rhythms in at least one type of cell. Some genes may have rhythm in the liver, but not the skin cells, for instance. “It’s normal to oscillate,” Herzog says. Trouble arises when those clocks get out of sync with each other, says neuroscientist Joseph Takahashi at the University of Texas Southwestern Medical Center in Dallas. For instance, genes such as cMyc and p53 help control cell growth and division. Scientists now know they are governed, in part, by the circadian clock. Disrupting the circadian clock’s smooth running could lead to cancer-promoting mistakes.
But while bad timing might lead to diseases, there’s also a potential upside. Scientists have also realized that giving drugs at the right time might make them more effective, Herzog says.
Rosbash joked during a news conference that his own circadian rhythms had been disrupted by the Nobel committee’s early morning phone call. When he heard the news that he’d won the prize, “I was shocked, breathless really. Literally. My wife said, ‘Start breathing,’” he told an interviewer from the Nobel committee.
Young’s sleep was untroubled by the call from Sweden. His home phone is the kitchen, and he didn’t hear it ring, so the committee was unable to reach him before making the announcement. “The rest of the world knew, but I didn’t,” he says. Rockefeller University president Richard Lifton called him on his cell phone and shared the news, throwing Young’s timing off, too. “This really did take me surprise,” Young said during a news conference. “I had trouble even putting my shoes on this morning. I’d go pick up the shoes and realize I needed the socks. And then ‘I should put my pants on first.’”
A new insect-inspired tiny robot that can move between air and water is a lightweight.
Weighing the same as about six grains of rice, it is the lightest robot that can fly, swim and launch itself from water, an international team of researchers reports October 25 in Science Robotics. The bot is about 1,000 times lighter than other previously developed aerial-aquatic robots. In the future, this kind of aquatic flier could be used to perform search-and-rescue operations, sample water quality or simply explore by air or sea. To hover, the bot flaps its translucent wings 220 to 300 times per second, somewhat faster than a housefly. Once submerged, the tiny robot surfaces by slowly flapping its wings at about nine beats per second to maintain stability underwater.
For the tricky water-to-air transition, the bot does some chemistry. After water has collected inside the machine’s central container, the bot uses a device to split water into hydrogen and oxygen gas. As the chamber fills with gas, the buoyancy lifts the vehicle high enough to hoist the wings out of the water. An onboard “sparker” then creates a miniature explosion that sends the bot rocketing about 37 centimeters — roughly the average length of a men’s shoe box — into the air. Microscopic holes at the top of the chamber release excess pressure, preventing a loss of robot limbs. Still, the design needs work: The machine doesn’t land well, and it can only pierce the water’s surface with the help of soap, which lowers the surface tension. More importantly, the experiment points to the possibilities of incorporating different forms of locomotion into a single robot, says study coauthor Robert Wood, a bioengineer at Harvard University.
Emma Watson, Jake Gyllenhaal, journalist Fiona Bruce and Barack Obama all walk into a sheep pen. No, this isn’t the beginning of a baaa-d joke.
By training sheep using pictures of these celebrities, researchers from the University of Cambridge discovered that the animals are able to recognize familiar faces from 2-D images. Given a choice, the sheep picked the familiar celebrity’s face over an unfamiliar face the majority of the time, the researchers report November 8 in Royal Society Open Science. Even when a celeb’s face was slightly tilted rather than face-on, the sheep still picked the image more often than not. That means the sheep were not just memorizing images, demonstrating for the first time that sheep have advanced face-recognition capabilities similar to those of humans and other primates, say neurobiologist Jennifer Morton and her colleagues.
Sheep have been known to pick out pictures of individuals in their flock, and even familiar handlers (SN: 10/6/12, p. 20). But it’s been unclear whether the skill was real recognition or simple memorization. Sheep now join other animals, including horses, dogs, rhesus macaques and mockingbirds, that are able to distinguish between individuals of other species. Morton and her colleagues released eight sheep one-by-one into a pen outfitted with two computer screens. A celebrity’s face would appear on one screen, while a different image appeared on the other. First, the team familiarized the sheep with the celebrities’ faces by showing the faces opposite a black screen or random objects. Picking the celebrity earned a sheep a food-pellet reward. Next, researchers paired a celebrity mug, like Gyllenhaal’s now-familiar face, with an unfamiliar person. By the end of this experiment, the sheep chose a familiar celebrity’s face over a stranger’s face about 79 percent of the time on average.
To see if the sheep were just memorizing shapes, researchers did the same test, but with pictures in which the celebs’ heads were tilted right or left. The sheep didn’t do as well but still passed, recognizing the celebrities about 67 percent of the time on average — a drop in performance comparable to that seen in humans performing the same task.
In a final test, the sheep had to choose between a picture of one of their handlers’ faces and an unfamiliar face. On her first try, one sheep appeared taken aback by the new face in the mix. She did a double take of both faces before ultimately choosing her handler. Since the handler cares for the sheep daily, the animals were familiar with her — although they had never seen a 2-D photo of her face. Recognizing a person that is familiar from 3-D life requires “complex image processing,” the authors say, because the sheep must translate their memory of the person to a 2-D picture.
Brad Duchaine, a brain scientist at Dartmouth College, doesn’t find the sheep’s ability surprising. “My guess is that the ability of sheep to recognize human faces is a by-product of selection to discriminate between different sheep faces,” he says. “Either the human face is similar enough to the sheep face that [it] activates the sheep face-processing system, or human-face recognition relies on more general-purpose recognition systems.”
Et tu, antibody? In humans, dengue can be more severe the second time around. Now, a study implicates an immune system treachery as the culprit.
The study suggests that the amount of anti-dengue antibodies a person has matters. In a 12-year study of Nicaraguan children, low levels of dengue antibodies left over in the blood from a prior infection increased the risk of getting a life-threatening form of the disease the next time around, researchers report online November 2 in Science.
Four related viruses cause dengue. The theory that antibodies protective against one type of dengue can collude with a different type of the virus to make a second infection worse was proposed in the 1960s. Such antibody-dependent enhancement has been shown in cells and lab animals. But “there’s been this controversy for five decades about, does this antibody-dependent enhancement really happen in dengue” in humans, says coauthor Eva Harris, a viral immunologist at the University of California, Berkeley’s School of Public Health. “And this says, yes, it does.”
About 2.5 billion people live where there is a risk of dengue infection. The virus infects 50 million to 100 million people every year, the World Health Organization estimates, but many cases go unreported. Infection with the mosquito-transmitted virus often leads to no symptoms, but can cause fever, joint and muscle pain and other flulike symptoms. The most severe form, which affects about half a million people annually, can include internal bleeding, respiratory distress or organ failure, and may be fatal. Getting sick with one of the four virus types can protect against a future infection of the same type. But in some cases, the theory goes, leftover antibodies from the first illness can actually help the second infection invade cells, increasing the risk of severe dengue disease.
“This study provides support for this idea that antibodies under certain conditions can be bad and actually cause severe disease when people are infected with dengue,” says viral immunologist Sujan Shresta of the La Jolla Institute for Allergy and Immunology in California. The next step, she says, is to learn more about the antibodies involved and see whether the findings hold up in other populations.
From 2004 to 2016, Harris and her colleagues studied more than 6,500 children aged 2 to 14 in Managua, Nicaragua. The researchers took blood samples each year, at a time when the kids were healthy, and assessed their antibody levels. The scientists also monitored which kids developed dengue and how severe the disease was.
An analysis showed that kids with a specific low range of anti-dengue antibodies had around a 7½ times higher risk of developing the most severe form of the disease than those who had either no antibodies or a high amount. The team’s test couldn’t tell what kind of dengue antibodies each child had. Harris and colleagues are now working on characterizing the antibodies measured in their test, to learn what makes them protective or harmful.
The new study supports the theory of antibody-dependent enhancement in humans, says Anna Durbin, an infectious diseases physician at Johns Hopkins Bloomberg School of Public Health. But she also argues that the risk of developing severe disease depends on the quality of the antibody — that is, how potent it is — as much as, or more than, the quantity. “A number in and of itself doesn’t tell you a whole lot.”
NEW ORLEANS — Saturn’s mighty rings cast a long shadow on the gas giant — and not just in visible light.
Final observations from the Cassini spacecraft show that the rings block the sunlight that charges particles in Saturn’s atmosphere. The rings may even be raining charged water particles onto the planet, researchers report online December 11 in Science and at the fall meeting of the American Geophysical Union.
In the months before plunging into Saturn’s atmosphere in September (SN Online: 9/15/17), the Cassini spacecraft made a series of dives between the gas giant and its iconic rings (SN Online: 4/21/17). Some of those orbits took the spacecraft directly into Saturn’s ionosphere, a layer of charged particles in the upper atmosphere. The charged particles are mostly the result of ultraviolet radiation from the sun separating electrons from atoms. Jan-Erik Wahlund of the Swedish Institute of Space Physics in Uppsala and Ann Persoon of the University of Iowa in Iowa City and their colleagues examined data from 11 of Cassini’s dives through the rings. The researchers found a lower density of charged particles in the regions associated with the ring shadows than elsewhere in the ionosphere. That finding suggests the rings block ultraviolet light, the team concludes.
Blocked sunlight can’t explain everything surprising about the ionosphere, though. The ionosphere was more variable than the researchers expected, with its electron density sometimes changing by more than an order of magnitude from one Cassini orbit to the next.
Charged water particles chipped off of the rings could periodically splash into the ionosphere and sop up the free electrons, the researchers suggest. This idea, known as “ring rain,” was proposed in the 1980s (SN: 8/9/86, p. 84) but has still never been observed directly.