Plastic cling wrap with nano-sized pores could give “cool clothes” a new meaning.
The material lets heat escape, instead of trapping it like traditional fabrics, Stanford University materials scientist Yi Cui and colleagues report in the Sept. 2 Science. It could help people keep cool in hot weather, Cui says, and even save energy by reducing the use of air conditioning.
“It’s a very bold new idea,” says MIT physicist Svetlana Boriskina, who wrote an accompanying commentary. Demand for the new material could be far-reaching, she says. “Every person who wears clothes could be a potential user of this product.” Current cooling devices include wearable fans and wicking fabrics; both rely on evaporation to cool human skin. But skin also sheds heat in another way — as infrared radiation. Clothing holds this heat close to the body, Cui says. If infrared radiation could instead pass through fabric, he reasoned, people would feel a lot cooler.
But the fabric would have to be transparent only to infrared wavelengths. To visible light, it would need to be opaque. Otherwise, the clothing would be see-through.
Cui found just one material that satisfied both requirements: a commercially available plastic used in lithium-ion batteries. The material, called nanoporous polyethylene, or nanoPE, is a cling wrap‒like plastic that lets infrared radiation through. But unlike cling wrap, the material isn’t clear: It blocks visible light.
Tiny pores speckled throughout the fabric act as obstacles to visible light, Boriskina says. When blue light, for example, hits the pores, it scatters. So do other colors. The light “bounces around in different directions and scrambles together,” she says. To human eyes, the resulting color is white.
The pores scatter visible light because they’re both in the same size range: The diameters of the pores span 50 to 1,000 nanometers, and the wavelengths of visible light range from 400 to 700 nanometers. Infrared light emitted by the body has a much larger wavelength, 7,000 to 14,000 nanometers, so the plastic’s tiny pores can’t block it. To infrared light, the pores are barely bumps in the road, not barriers. The pores are kind of like small rocks at a beach, Boriskina says. They’ll interfere with the motion of small waves, but big waves will wash right over.
Cui and colleagues tested nanoPE by laying it on a hot plate warmed up to human skin temperature — 33.5° Celsius. NanoPE raised the “skin” temperature by just 0.8 degrees(to 34.3° C). “But when you put on cotton, my God, it rose to 37,” Cui says. “It’s hot!”
The researchers also tried to make nanoPE more wearable than plastic wrap. They coated it with a water-wicking chemical, punched holes in it to make it breathable, and layered it with cotton mesh. Now, the team is working on weaving the fabric to make it feel more like traditional textiles.
“Within five years, I hope someone will start wearing it,” Cui says. “And within 10 years, I hope most people will be wearing it.”
A new map of the galaxy, the most precise to date, reveals positions on the sky for over 1 billion stars both within and beyond the Milky Way.
This new galactic atlas, courtesy of the European Space Agency’s Gaia spacecraft, also provides distances to roughly 2 million of those stars, laying the groundwork for astronomers who want to piece together the formation, evolution and structure of the Milky Way.
“This is a major advance in mapping the heavens,” Anthony Brown, an astrophysicist at Leiden University in the Netherlands, said September 14 at a news briefing. “Out of the 1 billion stars, we estimate that over 400 million are new discoveries.” There are no major cosmic revelations yet; those will develop in the months and years to come as astronomers pore over the data. This catalog of stars is just a first peek at what’s to come from Gaia, which is spending five years gathering intel on a wide variety of celestial objects.
The final survey will eventually provide a 3-D map of over 1 billion stars. It will also chart positions of roughly 250,000 asteroids and comets within the solar system, 1 million galaxies, and 500,000 quasars — the blazing cores of galaxies lit up by gas swirling around supermassive black holes. Mission scientists also expect they will turn up over 10,000 undiscovered planets orbiting other stars.
“It’s a very democratic mission,” said project scientist Timo Prusti. “Anything that looks like a [point of light] gets caught up and observed.”
Gaia launched on December 19, 2013, and eventually settled into its home about 1.5 million kilometers from Earth on an orbit that follows our planet around the sun (SN Online: 12/19/13). Regular science observations started in July 2014. This first data release, described in a series of papers being published online starting September 14 in Astronomy & Astrophysics, contains data obtained through September 2015.
The spacecraft repeatedly scans the sky with two telescopes pointed in different directions. To make the 3-D map, Gaia measures each star’s parallax, a subtle apparent shift in the position of the star caused by the changing viewing angle as the spacecraft loops around the sun. By measuring the amount of parallax, and knowing the size of Gaia’s orbit, astronomers can triangulate precise distances to those stars. With distances in hand, astronomers can figure out how intrinsically bright those stars are, which in turn will help researchers understand how stars evolve. A detailed stellar map could also help chart the Milky Way’s distribution of dark matter, the elusive substance that is thought to make up the bulk of the mass in all galaxies and reveals itself only through gravitational interactions with stars and gas.
One controversy that astronomers are eager to resolve with Gaia is the distance to the Pleiades star cluster, one of the closest repositories of youthful stars. A previous Gaia-like mission, the Hipparcos satellite, came up with a distance of about 392 light-years. Estimates based on simulations of how stars evolve as well as observations from the Hubble Space Telescope and ground-based radio observatories pin the Pleiades at about 443 light-years away (SN Online: 4/28/14).
“Clusters give you a sense of the evolution of stars at different ages,” says Jo Bovy, an astrophysicist at the University of Toronto who is not involved with the Gaia mission. “The Pleiades is a nearby cluster that we can study well — it’s one of the cornerstones.” All of the stars in the Pleiades are roughly 100 million years old, and so provide a snapshot of a relatively young stellar age. Nailing down the distance reveals the intrinsic brightness of the stars, which is crucial to understanding how stars develop in their early years.
Gaia appears to be leaning toward the larger distance, Brown said, but there’s still too much uncertainty in the data to say anything definitive. “It’s too early to say how the controversy will be resolved. But Gaia will pin it down.”
The Pleiades distance debate, as well as a clearer picture of how the Milky Way is put together, will have to wait for future data releases from Gaia. The next release is planned for late 2017; the final catalog won’t be available until 2022.
“Those will be much more interesting,” Bovy says. “Then we can actually start using our modeling machinery and see how stars are distributed throughout the galaxy. We can test our understanding of dark matter and our understanding of how the Milky Way formed.”
Researchers have digitally unwrapped and read an ancient Hebrew scroll that’s so charred it can’t be touched without falling apart. It turns out the document contains the oldest known Biblical text outside of the roughly 2,000-year-old Dead Sea Scrolls, the investigators say.
Archaeologists discovered the scroll’s remnants in a synagogue’s holy ark during a 1970 excavation in Israel of En-Gedi, a Jewish community destroyed by fire around 600.
In a series of digital steps, slices from a 3-D scan of the En-Gedi scroll were analyzed to bring letters and words into relief on a pieced-together, virtual page. Those images revealed passages from the book of Leviticus written in ink on the scroll’s disintegrating sheets. Radiocarbon results date the scroll to approximately 300, making it the earliest copy of an Old Testament book ever found in a holy ark, scientists report September 21 in Science Advances.
This computerized recovery and conservation process can now be used to retrieve other ancient documents “from the brink of oblivion,” the researchers say.
DENVER — A period of skyrocketing global temperatures started with a bang, new research suggests.
Impact debris and evidence of widespread wildfires around eastern North America suggest that a large space rock whacked Earth around 56 million years ago at the beginning of the Paleocene-Eocene Thermal Maximum, also known as the PETM, a period of rapid warming and huge increases in carbon dioxide. The event is one of the closest historic analogs to modern global warming and is used to improve predictions of how Earth’s climate and ecosystems will fare in the coming decades. Too little is known about the newfound impact to guess its origin, size or effect on the global climate, said geochemist Morgan Schaller of Rensselaer Polytechnic Institute in Troy, N.Y. But it fits in with the long-standing and controversial proposal that a comet impact caused the PETM. “The timing is nothing short of remarkable,” said Schaller, who presented the discovery September 27 at the Geological Society of America’s annual meeting.
The impact may have contributed to the rapid rise in CO2 by stirring carbon up into the atmosphere, but it was hardly the sole cause, said Sandra Kirtland Turner, a geochemist at the University of California, Riverside. Her own environmental simulations suggest that the influx of carbon that flooded Earth during the PETM probably took place over at least 2,500 years, far too drawn out to be caused by a single event, she said at the same meeting.
During the PETM, a massive influx of carbon flooded the atmosphere (SN: 5/30/15, p. 15) and Earth warmed by 5 to 8 degrees Celsius to temperatures much hotter than today. That carbon dump altered the relative abundance of different carbon isotopes in the atmosphere and oceans, leaving a signal in the sedimentary record.
While searching for that signal in roughly 56-million-year-old sediments from sites up and down the U.S. East Coast, Schaller spotted microscopic glassy spheres about the size of a dust mite. These specks resemble those blasted from previously identified large impact events. After switching from a black to a white sorting tray to more easily see the black debris, one of Schaller’s Rensselaer colleagues, micropaleontologist Megan Fung, discovered abundant charcoal pieces in the mix. That charcoal formed when wildfires sparked by the impact raged across the landscape, she proposed.
More evidence of the impact will help researchers to better constrain its location, scope and possible relationship to the start of the PETM, Schaller said.
Condensing billions and billions and billions of years into a 45-minute film is a tall order. But director Terrence Malick took on the challenge with Voyage of Time. The film, now playing in IMAX theaters, surveys the 13.8-billion-year history of the universe and even looks eons into the future when we — life on Earth, the planet and the entire solar system — are gone.
Starting with the Big Bang, Voyage of Time progresses through highlights of the past, with a central focus on the evolution of life. Malick, best known for directing visually rich dramas such as The Thin Red Line and The Tree of Life, presents breathtaking cinematography, using locales such as Hawaii’s lava-oozing Kilauea volcano as stand-ins for the past. Stunning visualizations and special effects bring to life the formation of the planets, the origin of the first cells, the demise of the sun and other events that scientists can only imagine. The film marks Malick’s first attempt at documentary filmmaking. If you can call it that. Viewers hoping for a David Attenborough–style treatment of the subject matter will be disappointed. The film is more evocative, with moody scenes that provide little explication. And what narration (by Brad Pitt) there is tends to be philosophical rather than informative.
Serious science enthusiasts may find some reasons to quibble with the movie. For one, it’s hard to grasp the true immenseness and scale of cosmic time. With so much screen time devoted to the evolution of life, many viewers may not realize just how relatively recent a phenomenon it is. After the Big Bang, more than 9 billion years passed before Earth began to form. It took many hundred thousand more years before the first microbes emerged. Malick’s treatment of evolution may also rankle some viewers. At times, the narration seems to imply life was destined to happen, with the young, barren Earth just waiting around for the first seeds of life to take root. At other times, the narration imbues evolution with purpose. Pitt notes, for instance, that perfecting a leaf took eons. Yet perfection is something evolution neither achieves nor strives for — it’s a process that lacks intentionality.
These critiques aside, Malick sought to tell an accurate story, enlisting an accomplished group of scientists as advisers, including Lee Smolin of the Perimeter Institute for Theoretical Physics in Waterloo, Canada. Smolin says he was impressed with the end result. “It’s a very unusual film,” he says, likening it to a visual poem or piece of art.
And that’s probably the best mindset to watch Voyage of Time: Just sit back, soak in the dazzling visuals and contemplate the wonders of nature.
Michael Snyder’s genes were telling him that he might be at increased risk for type 2 diabetes. The Stanford University geneticist wasn’t worried: He felt healthy and didn’t have a family history of the disease. But as he monitored other aspects of his own biological data over months and years, he saw that diabetes was indeed emerging, even though he showed no symptoms.
Snyder’s story illustrates the power of looking beyond the genome, the complete catalog of an organism’s genetic information. His tale turns the genome’s one-dimensional view into a multidimensional one. In many ways, a genome is like a paper map of the world. That map shows where the cities are. But it doesn’t say anything about which nations trade with each other, which towns have fierce football rivalries or which states will swing for a particular political candidate. Open one of today’s digital maps, though, and numerous superimposed data sources give a whole lot of detailed, real-time information. With a few taps, Google Maps can show how to get across Boston at rush hour, offer alternate routes around traffic snarls and tell you where to pick up a pizza on the way.
Now, scientists like Snyder are developing these same sorts of tools for biology, with far-reaching consequences. To figure out what’s really happening within an organism — or within a particular organ or cell — researchers are linking the genome with large-scale data about the output of those genes at specific times, in specific places, in response to specific environmental pressures. While the genome remains mostly stable over time, other “omes” change based on what genes are turned on and off at particular moments in particular places in the body. The proteome (all an organism’s proteins) and the metabolome (all the metabolites, or small molecules that are the outputs of biological processes) are two of several powerful datasets that become more informative when used together in a multi-omic approach. They show how that genomic instruction manual is actually being applied. “The genome tells you what can happen,” says Oliver Fiehn, a biochemist at the University of California, Davis. The proteome and the metabolome can show what’s actually going on.
And just as city planners use data about traffic patterns to figure out where to widen roads and how to time stoplights, biologists can use those entwined networks to predict at a molecular level how individual organisms will respond under specific conditions.
By linking these layers and others to expand from genomics to multi-omics, scientists might be able to meet the goals of personalized medicine: to figure out, for example, what treatment a particular cancer patient will best respond to, based on the network dynamics responsible for a tumor. Or predict whether an experimental vaccine will work before moving into expensive clinical tests. Or help crops grow better during a drought.
And while many of those applications are still in the future, researchers are laying the groundwork right now.
“Biology is being done in a way that’s never been done before,” says Nitin Baliga, director of the Institute for Systems Biology in Seattle.
Data dump Scientists have long studied how genes influence traits. Researchers have figured out important connections between genes and the proteins they encode and have scoured the genome for associations between particular genetic mutations and diseases. But a gene-by-gene view of the body is like trying to diagnose a citywide traffic problem by looking at just one backed-up intersection.
“There are so many places that a system can go awry,” Baliga says. When dozens of genes are working together, it’s tricky to tease out which one is misfiring in a particular instance.
Baliga is among a growing group of scientists who want to study life through a systems lens, because sometimes that traffic jam at one intersection is being caused by an out-of-sight accident three blocks away.
Such an approach is particularly useful for unraveling the complexities of diseases like cancer and diabetes. These conditions involve a tangled web of genes, paired with lifestyle factors and environmental conditions — Is she a smoker? How much does she exercise? — that influence when those various genes are turned on and off. Reconstructing the tangled routes by which genes interact to influence the body is a slightly more complicated feat than mapping the best path from Tulsa to Tuscaloosa. For one thing, it requires serious computer power to gather, store and analyze all that data. The 3 billion chemical coding units that string together to form a person’s inventory of DNA, if entered into an Excel spreadsheet line-by-line, would stretch about 7,900 miles. The human proteome contains more than 30,000 distinct proteins that have been identified so far. And researchers have cataloged more than 40,000 different human metabolites, such lactic acid, ethanol and glucose.
Working with such big datasets can be expensive, too. Compiling the first human genome took 10 years and cost almost $3 billion. Now, the costs of collecting and analyzing all these datasets have come down, so it’s finally feasible to use them in tandem to answer big biological questions.
The important players Scientists would like to understand the interplay between the genome and the proteome. Add in the metabolome. To make things more complex, there’s the epigenome — the chemical modifications to DNA that help control which genes are turned on and off — and the transcriptome, the full range of RNAs that translate DNA’s blueprints so they can be used to make proteins. It’s no surprise that mapping such a comprehensive network for any organism is still a distant goal.
For now, scientists tend to focus their multi-omic studies on a particular disease or question. Baliga wants to learn how tuberculosis — which sickens nearly 10 million people per year and kills 1.5 million — evades drugs within the body. Many strains of the TB bacterium are resistant to existing treatments or can tolerate them long enough to establish a strong foothold.
To learn how Mycobacterium tuberculosis mounts a defense against a drug, Baliga is first looking within the bacterium, identifying the genes, proteins and other molecules that interact as the microbe infects a host.
He collects different types of omic data from M. tuberculosis alone and when it’s in the presence of an antibiotic. His team recently focused on the microbe’s response to bedaquiline, a drug used to treat multidrug-resistant TB. Baliga measured the microbe’s transcriptome in the presence of different doses of bedaquiline and at different times after introducing the drug.
From this giant data dump, computer models helped narrow the focus to a smaller collection of genes, proteins and other molecules that changed under certain conditions. Visualization programs turned these mathematical outputs into maps that scientists could analyze.
About 1,100 genes behaved differently in the presence of bedaquiline, Baliga’s team reported in August in Nature Microbiology. Measurements of the RNA indicated that most of those genes became less active, but a few shifted into overdrive. The researchers suspected those hyperactive genes might be behind the resistance — playing off each other to create a smaller network within the larger tuberculosis response network.
But statistical analysis alone wasn’t enough to confirm the hunch. Correlation isn’t cause, Fiehn points out. Scientists need to figure out which of those changes actually matter. That is, if you’re scanning millions of data points looking for variation, you’re going to find certain abnormalities that are due to chance and are unrelated to the disease or question at hand. But starting from that smaller dataset of outputs that change, scientists can then test which players are actually important in the network and which belong on the sidelines. In animal models or petri dishes, scientists disable one gene at a time to see how it affects the proposed network.
“Systems biology has been able to generate these amazing hypotheses about how genes interact,” Baliga says. Testing them has historically been more challenging. But now, gene-editing technologies such as CRISPR/Cas9 (SN: 9/3/16, p. 22) allow scientists to more easily test these networks in living systems.
Baliga and his team edited the genome of M. tuberculosis, disabling the regulatory machinery responsible for some of the overactive genes. Sure enough, the drug worked better on the modified bacteria, the researchers reported.
Networking solutions Once a network has been mapped, scientists can use it to predict (and maybe even prevent) illness.
Baliga’s team identified a second drug that works with bedaquiline. The drug turns off some of the regulators for the overactive tuberculosis gene network that was fighting off the bedaquiline. Using the second drug with bedaquiline made tuberculosis bacteria more vulnerable, pointing to a potential strategy for dealing with persistent infections.
Baliga’s group is also mapping networks in patients with glioblastoma, a particularly deadly type of brain tumor. In the August Cell Systems, the scientists described work designed to figure out why some patients respond to certain drugs while others don’t. The aim is to personalize treatments, to choose a drug that targets the particular network glitch that gives rise to that patient’s tumor, Baliga says. The drug might ramp up production of a protein that’s currently in short supply, or turn off a gene that’s mistakenly on. That same drug might be completely useless for another patient whose tumor developed through a different network error.
“Being able to do that systematically across all cancers, using networks — that has not happened yet,” Baliga says. But scientists have devised drug treatments to address individual mutations. And expanding that to a greater range of cancers in the future is not farfetched, he says.
Other scientists are using multi-omic approaches for preventive medicine, for example, to be more effective and efficient in vaccine development. Despite years of trying, scientists still haven’t created an HIV vaccine that can protect people against the virus, says Alan Aderem, a biologist at the Center for Infectious Disease Research in Seattle. Bringing a vaccine from test tube to market is costly and time-consuming. With a better understanding of how the networks of the body’s immune system respond to the disease, researchers could be more selective in the vaccine candidates that they invest time and money in developing.
“The real value of systems biology is that it’s predictive,” Aderem says. “If you could predict upfront if a vaccine would work, you’d not only save a huge amount of energy, you’d also save a huge amount of lives.”
Plant power Multi-omics has perhaps received the most attention in the context of human health — but that’s also the realm where it’s hardest to piece together the omic layers. Because simpler organisms can be manipulated genetically, it’s easier to move from networks on a computer screen to real solutions. For instance, some scientists are using multi-omic analysis to engineer networks that let crop plants thrive with less water. To turn carbon dioxide into sugar via photosynthesis, plants need a lot of water. But some desert plants make do with less. Most plants take in carbon dioxide through small pores in their leaves. Opening these pores can let water evaporate out. In the desert, where water is in short supply, some plants use a different network of chemical reactions to make energy: crassulacean acid metabolism, or CAM.
Plants that use CAM open pores in their leaves only during the cooler nighttime, when water is less likely to evaporate out. They store the CO2 they take in until daytime, when they close the pores and convert the CO2 into food.
“Our goal is to move this metabolic trick into crop plants,” says John Cushman, a biochemist at the University of Nevada, Reno. “In order to do that, you have to understand the complexity of all the enzymes and regulatory components associated with the circadian clock of the plant.”
Cushman’s team has collected vast omic datasets from CAM plants. He estimates that several hundred genes coordinate the process, turning each other on and off and producing proteins that interact with each other and influence other genes.
His team is trying to engineer the plant Arabidopsis (a weed often used for genetic experiments) to use CAM by inserting the relevant genes into the plant. If they can get it to work in this small lab plant, the researchers want to do the same in poplar trees to help grow biofuel sources in harsh environments not usually suitable for agriculture. Someday, Cushman hopes, the technology will help food crops grow better in arid climates.
Better than a hunch So far, collecting and integrating omic data is largely restricted to the lab — the work is still expensive and time-consuming. But scientists like Snyder, who diagnosed himself with type 2 diabetes, think that someday people could regularly collect these sorts of data to track changes in their health over time.
The Stanford geneticist began by analyzing his own genome. Then he started measuring his proteome, metabolome and other omic data at regular intervals to develop what he termed his “personal omics profile.”
Certain mutations in his genome suggested that he was at risk for developing diabetes from the get-go. He was surprised, but didn’t take action. Nearly a year into his experiment, though, changes in his other omic data suggested that his body was no longer using glucose properly. His blood sugar was elevated and so was a type of hemoglobin that increases with uncontrolled diabetes, according to a report in Cell by Snyder and three dozen colleagues in 2012. Those aren’t new measures — they’re exactly what a doctor would test in someone with diabetes symptoms. But Snyder had no symptoms. He had just had a nasty cold, which he now thinks may have triggered the onset of diabetes because he was already genetically at risk.
Because he spotted the changes early and his doctor confirmed he had diabetes, Snyder was able to fend off symptoms by changing his diet and exercise habits — which was reflected in the follow-up data he collected.
He monitored how other biological measurements (molecules that standard medical diagnostic tests might not even look at) changed with the onset of his diabetes and the lifestyle changes he made in response. That information might be valuable for doctors hoping to detect the onset of diabetes in patients before symptoms appear. So now his lab is tracking omic data from 100 people, most of whom have elevated blood sugar levels, but have not yet been diagnosed with diabetes. Snyder wants to see whether viral infections trigger diabetes in other people, or whether his case is an isolated incident.
Snyder is still tracking fluctuations in his own data over time, too. He thinks it’s a powerful tool for personalized medicine because it shows in real time how an individual responds to disease and other stressors.
“You’ll be able to start linking disease to treatment to outcomes,” Snyder says. “It becomes what I call data-driven medicine, instead of hunch-driven medicine.” Making sense of this sort of data isn’t easy. “No story is the same,” Snyder says. “We see a lot of strange stuff that we don’t know how to interpret yet.”
But collecting detailed omic-level data about individuals over time could still be useful, he says. By collecting more data from healthy people, doctors and scientists could get a better sense of what’s normal. And tracking fluctuations in individual patients’ data over time can show what’s typical for that particular person. Snyder thinks that might be more valuable than knowing what’s normal for people in general. Someone monitoring these biological signs might notice molecular changes — as he did — before they cause troublesome physical symptoms.
For the multi-omic future that Snyder and others envision, scientists will need a greater ability to store and wrangle massive amounts of data than they possess today. And they’ll need ways to test the networks they uncover. But the potential payoff is enormous: A response map that can display the intertwining routes between genes and outcomes, as well as how distant red lights, speed bumps and construction zones play off each other to shift those paths.
Two more teeny moons might be lurking around Uranus. That’s in addition to the 27 we already know about. Fluctuations in the density of two of the planet’s dark rings, seen in radio data from the 1986 flyby of the Voyager 2 spacecraft, could be caused by unseen moonlets, Robert Chancia and Matthew Hedman, astronomers at the University of Idaho in Moscow, report online October 9 at arXiv.org.
At probably just 4 to 14 kilometers wide, both moons would be very difficult to detect in Voyager 2 images, the researchers report. New observations with ground-based telescopes might have better luck.
Electron microscopy is finally getting its Kodachrome moment.
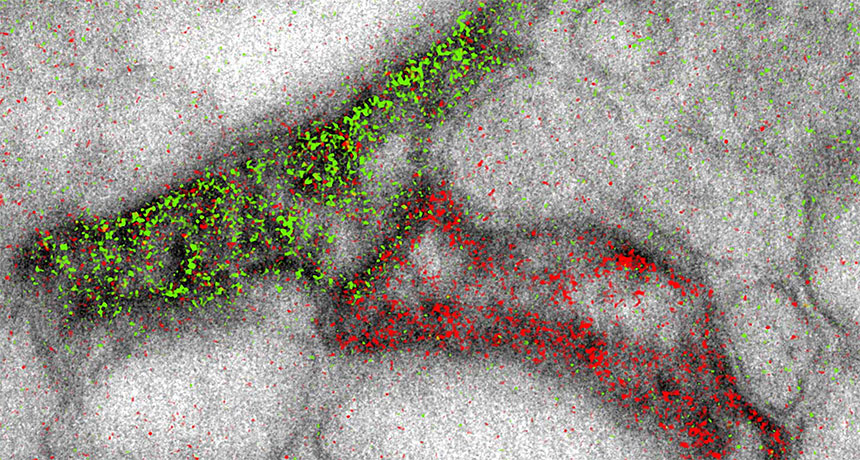
The high-powered scopes can now produce images that simultaneously highlight different molecules in different colors, scientists report online November 3 in Cell Chemical Biology. That’s helpful for researchers hoping to visualize the complex structures of cells or tissues — such as connections between brain cells, shown here.
Electron microscopes build black-and-white images by shooting beams of electrons at samples. Previously, scientists could add color by overlaying lower-resolution images from light microscopes. The new technique adds pizzazz without sacrificing image quality. It involves sequentially layering different metal ions on top of the sample. Each ion selectively latches onto a different target molecule. The electron beam interacts differently with each ion, yielding signature wave shapes that can be converted into colors. The researchers used the coloring technique to show that two brain cells called astrocytes (the edge of one shown in green, the other in red) could link up to the same message-sending junction between nerve cells.
Traffic jams in the brain’s blood supply may play a role in Alzheimer’s disease. A new online game turns people at home into amateur traffic cops. This policing, which involves spotting hard-to-see sluggishness in tiny capillaries in mice, may ultimately help scientists better understand, and perhaps even treat, Alzheimer’s, a devastating disorder that affects over 5 million Americans.
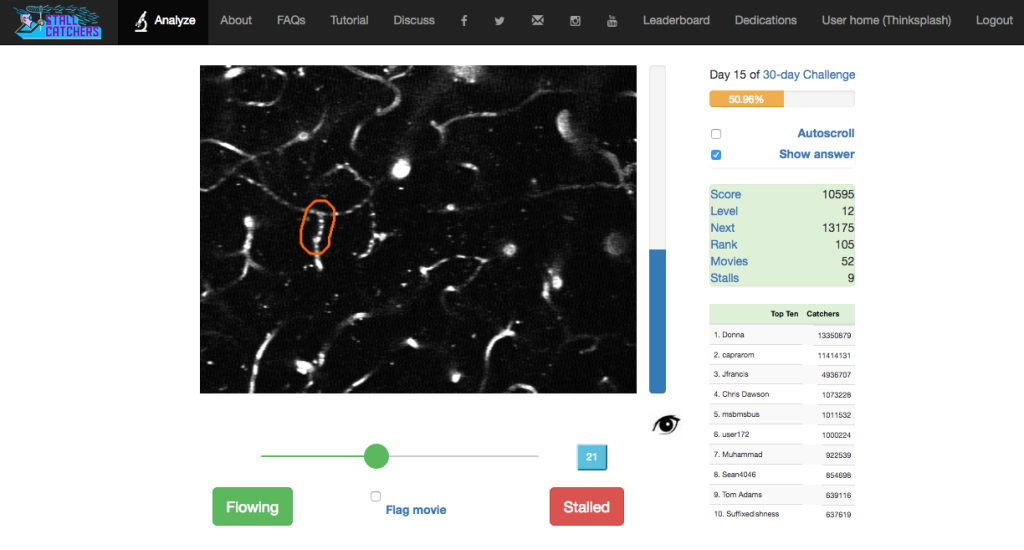
The science behind the game, called Stall Catchers, comes from Cornell University. Chris Schaffer, Nozomi Nishimura and colleagues found that mice designed to exhibit symptoms similar to Alzheimer’s have more blocked blood vessels in their brains than regular mice. That difference can deprive the brain of sustenance and may be a key to understanding how Alzheimer’s damages the brain, the researchers suspect. But finding congested capillaries is a slog. Computers haven’t been up to snuff, and experts could spend an entire year analyzing the thousands of microscope images needed to amass enough data to explore links between Alzheimer’s and blocked vessels. “I thought, if we could change that, it would be tremendous,” says Pietro Michelucci, director of the Human Computation Institute in Fairfax, Va. The institute is a nonprofit organization that runs the EyesOnALZ program, which aims to crowdsource Alzheimer’s research.
That’s where StallCatchers.com comes in. The website asks players to sift through short black-and-white videos of real mouse brains, on the prowl for blocked blood vessels. In the videos, moving blood appears white. But stationary black segments that appear between two white segments signal trouble — a stall. Players rack up points and ascend levels as they classify vessels. With practice, the task gets easier. And people who suffer from performance anxiety shouldn’t fret; each video will be scrutinized by multiple users to get the final verdict. With a little help from the crowd, “not only do [researchers] get answers faster, but they can ask more questions,” Michelucci says.
So far, nearly 1,000 users have played Stall Catchers, Michelucci says. Those players are beginning to generate data that will let researchers see how good these amateur traffic cops are. With luck, their eyes will help unstall the fight against Alzheimer’s.
NEW ORLEANS — Popular heartburn drugs — already under investigation for possible links to dementia, kidney and heart problems (SN: 6/11/16, p. 8) — have a new health concern to add to the list. An analysis of almost 250,000 medical records in Denmark has found an association with stroke.
Researchers from the Danish Heart Foundation in Copenhagen studied patients undergoing gastric endoscopy from 1997 to 2012. About 9,500 of all patients studied suffered from ischemic strokes, which occur when a blood clot blocks a blood vessel in the brain.
Overall, the risk of stroke was 21 percent higher in patients taking a proton pump inhibitor, a drug that relieves heartburn, the researchers reported November 15 during the American Heart Association’s annual meeting. While those patients also tended to be older and sicker to start with, the level of risk was associated with dose, the researchers found. People taking the lowest drug doses (between 10 and 20 milligrams a day, depending on the drug) did not have a higher risk. At the highest doses, though, Prevacid (more than 60 mg/day) carried a 30 percent higher risk and Protonix (more than 80 mg/day) a 94 percent higher risk. For Prilosec and Nexium, stroke risk fell within that range.
Introduced in the 1980s, proton pump inhibitors are available in both prescription and over-the-counter forms. While they are valuable drugs, “their use has been increasing rapidly,” says lead author Thomas Sehested, adding that people often take them for too long, or without a clear reason. Before taking them, he says, “patients need a conversation with their doctor to see if they really need these drugs.”